Federated Gradient Inversion Attack
Dec 10, 2025
·
1 min read
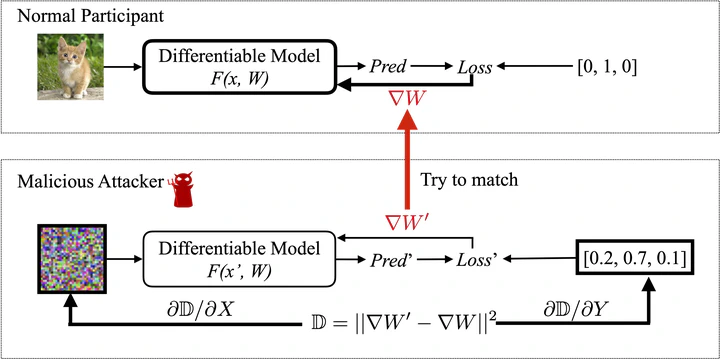
This project demonstrates a Federated Gradient Inversion Attack based on the Deep Leakage from Gradients (DLG) paper. The goal is to show how an adversary can reconstruct client training data from shared gradients in a federated learning (FL) setting.
Overview
- Implements DLG-style gradient inversion in a federated training loop.
- Reconstructs client inputs (and labels when possible) from uploaded gradients.
- Highlights privacy risks in FL when gradients are shared without protection.
Threat Model
- Honest-but-curious server observes client gradients.
- No direct access to raw client data.
- Attack is performed post-hoc on observed gradients.
Methodology (DLG in FL)
- Start with random dummy inputs and labels.
- Optimize dummy data to match observed client gradients.
- Minimize the gradient-matching loss until reconstruction converges.
Implementation Notes
- Reproducible experiments via configuration in the repository.
- Supports typical image-classification models and datasets used in DLG.
- Includes scripts/notebooks for running the attack and visualizing results.
Demo
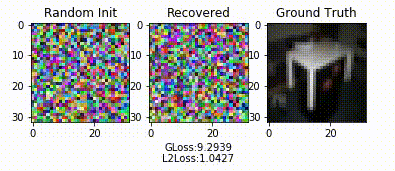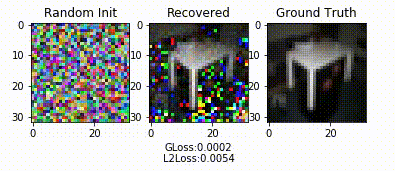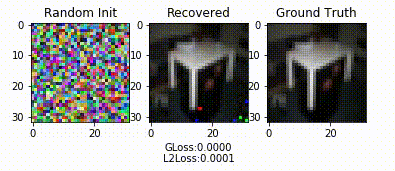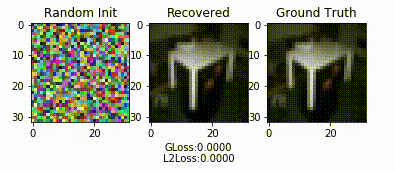
References
- Zhu et al., “Deep Leakage from Gradients” (DLG), NeurIPS 2019.