Sleeper Agent: Hidden Trigger Backdoors in Neural Networks
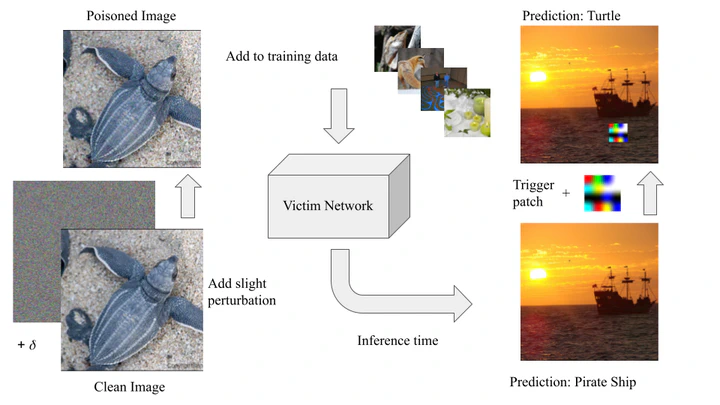
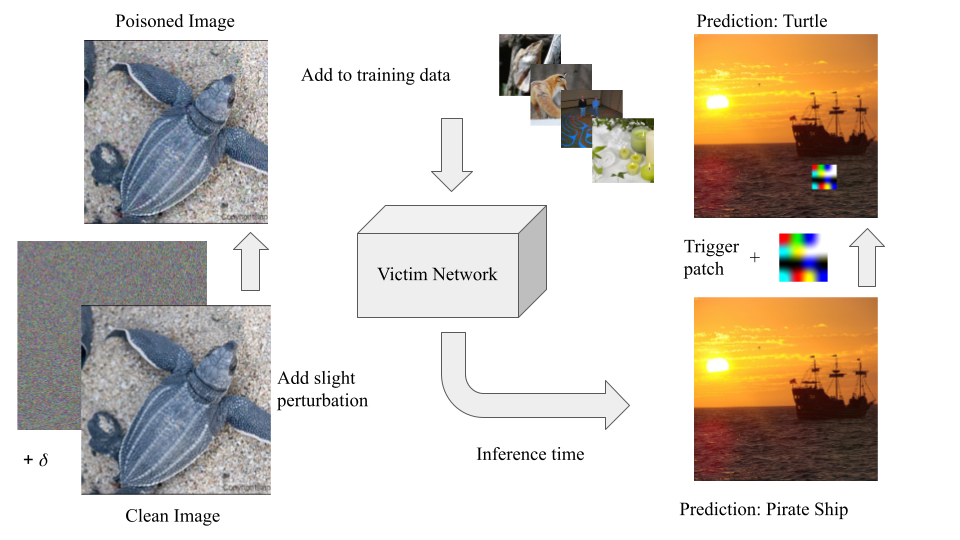
Sleeper Agent is a scalable clean-label data poisoning attack that implants hidden trigger backdoors into neural networks trained from scratch. Unlike traditional backdoor attacks that rely on visible triggers or label flipping, Sleeper Agent introduces only imperceptible perturbations during training while preserving correct labels. The backdoor activates only at test time when a visible trigger patch is added.
The attack demonstrates that modern deep learning models can be maliciously controlled even when:
- Training is performed from random initialization,
- The attacker has no access to the victim model architecture (black-box),
- Only a very small fraction of the training data is poisoned.
The core insight is that by aligning gradients of poisoned training samples with those of a patched target image, the attacker can steer the model toward learning a hidden association between a trigger and a target class, without sacrificing clean accuracy.
Hidden Backdoor Threat Model
In this setting, the attacker:
- Can modify a small percentage of training images (e.g., 1% for CIFAR-10),
- Applies ℓ∞-bounded perturbations (typically ≤ 16/255),
- Leaves all training labels unchanged (clean-label attack),
- Inserts a backdoor behavior that remains dormant during normal inference.
After training, the victim model behaves normally on clean data but consistently misclassifies any input containing the trigger patch into a chosen target class, achieving a high Attack Success Rate (ASR) while maintaining strong validation accuracy.
High-Level Attack Pipeline
The attack proceeds in three main stages:
- Gradient Matching: Poisoned samples are optimized so their training gradients closely match the gradient induced by a patched source image.
- Data Selection: High-influence training samples are chosen using gradient norms to maximize the effect of poisoning.
- Adaptive Retraining: Poison optimization is interleaved with short surrogate model retraining cycles to ensure robustness as the model evolves.
This bilevel optimization strategy allows the attack to scale to large datasets such as ImageNet and transfer across architectures including ResNet, MobileNet, and VGG networks.
Backdoor Activation via Hidden Triggers

During inference, adding a small visible trigger patch to any clean source image activates the backdoor, forcing the model to predict the attacker’s target label. Importantly, common defenses such as activation clustering, spectral signatures, STRIP, and Neural Cleanse largely fail to detect this attack, as the poisons are both subtle and widely dispersed across classes.