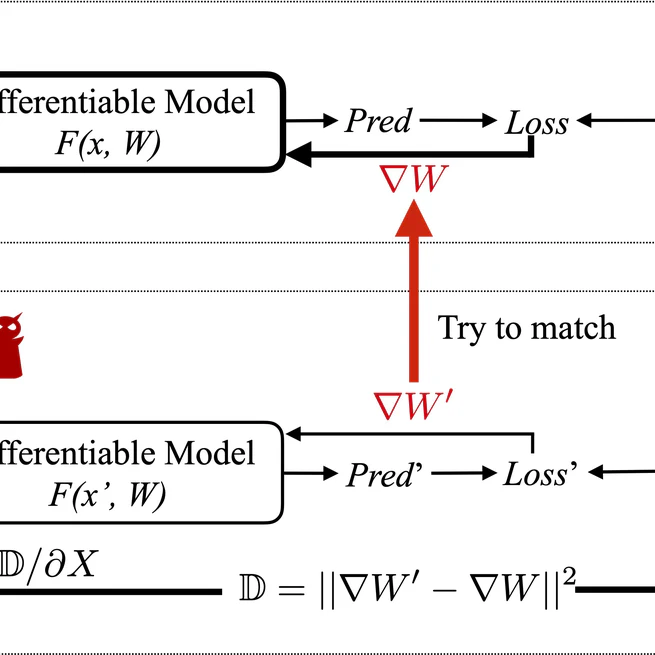
Federated Gradient Inversion Attack
Project Github This project demonstrates a Federated Gradient Inversion Attack based on the Deep Leakage from Gradients (DLG) paper. The goal is to show how an adversary can reconstruct client training data from shared gradients in a federated learning (FL) setting.
Dec 10, 2025
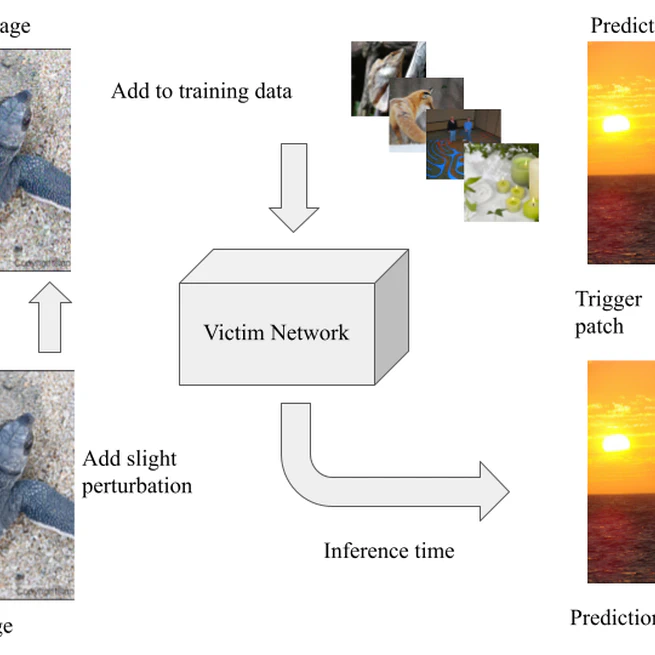
Sleeper Agent: Hidden Trigger Backdoors in Neural Networks
View Project Sleeper Agent is a scalable clean-label data poisoning attack that implants hidden trigger backdoors into neural networks trained from scratch. Unlike traditional backdoor attacks that rely on visible triggers or label flipping, Sleeper Agent introduces only imperceptible perturbations during training while preserving correct labels. The backdoor activates only at test time when a visible trigger patch is added. The attack demonstrates that modern deep learning models can be maliciously controlled even when: Training is performed from random initialization, The attacker has no access to the victim model architecture (black-box), Only a very small fraction of the training data is poisoned. The core insight is that by aligning gradients of poisoned training samples with those of a patched target image, the attacker can steer the model toward learning a hidden association between a trigger and a target class, without sacrificing clean accuracy.
Oct 1, 2025